Matches
- Importing data
Press the import button, also shown as >> when the interface is small, to import data into the list.The following file types are supported:
CSV (Comma delimited) (*.csv)
Text (Tab delimited) (*.txt)
All Files (*.*)
The data should be separated by commas, tab characters or newlines.
Each data entry must match the validation wildcard '*@*.*'. Entries that do not match will be discarded.
Duplicate entries are not imported more than once. - Importing data
Press the import button, also shown as >> when the interface is small, to import data into the list.The following file types are supported:
CSV (Comma delimited) (*.csv)
Text (Tab delimited) (*.txt)
All Files (*.*)
The data should be separated by commas, tab characters or newlines.
Duplicate entries are not imported more than once. - Importing data
Press the import button, also shown as >> when the interface is small, to import data into the list.The following file types are supported:
CSV (Comma delimited) (*.csv)
Text (Tab delimited) (*.txt)
All Files (*.*)
The data should be separated by commas, tab characters or newlines.
Duplicate entries are not imported more than once.

Priority
The rule priority/precedence. When matching just one rule the rule matched will be selected based on this priority/precedence measure. Lower numbers will be tested for matches first.
Once a match is found no further rules will be processed. If best match is selected rules with equal numbers of criteria will be matched preferentially based on this setting. Rules with equal priority settings
will be preferentially selected based on the highest number of match criteria.

0 - 999
9
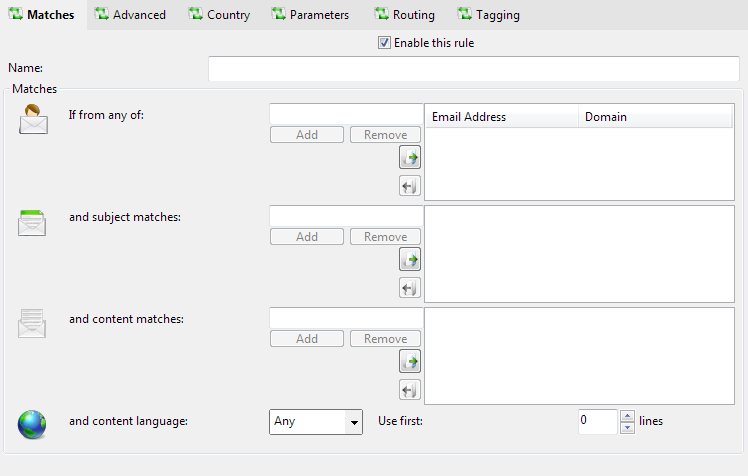
Matches
If from any of
email from any of these addresses will be routed. Leave blank to match for all emails (equivalent to *)

forbidden@example.com
and subject matches
email with subjects that match any of these wildcard/phrase/substring will be routed. Leave blank to match for all emails (equivalent to *)

and content matches
The text and html content parts of the email are scanned for the content match expressions. The expressions are substrings and can include the wildcards * ('one or more of any character') and ? ('any single character')


